从事件溯源到事件驱动:事件和事件流相关技术盘点

本文是读完Martin Kleppmann的《Making sense of stream processing》的一些理解和感悟。
Event Sourcing (事件溯源)、Stream processing(流处理)、Complex Event Processing(复杂事件处理)、CQRS(Command Query Responsibility Segregation,命令查询职责分离)、Event-driven architecture(事件驱动架构)等令人眼花缭乱的技术术语的本质是事件和事件流,这些技术的区别在于对事件的粒度的划分和对事件处理过程的侧重点。
1.Event Sourcing (事件溯源)
Event Sourcing侧重于事件的持久化,这里的事件的粒度可以细到对业务数据的增删改查,如果和传统的关系型数据库做对比,传统的关系型数据库记录的数据是一种最终状态,这个状态可以被随时增删改查,而Event Sourcing记录的数据则是对状态进行增删改的有序命令流,每条数据本省不可被更改,但依据这些命令流可以构造出最终的状态:
正如Martin所举的电商购物车的例子,传统的关系型数据库表中记录的是用户、商品和数量的信息,是最终结果: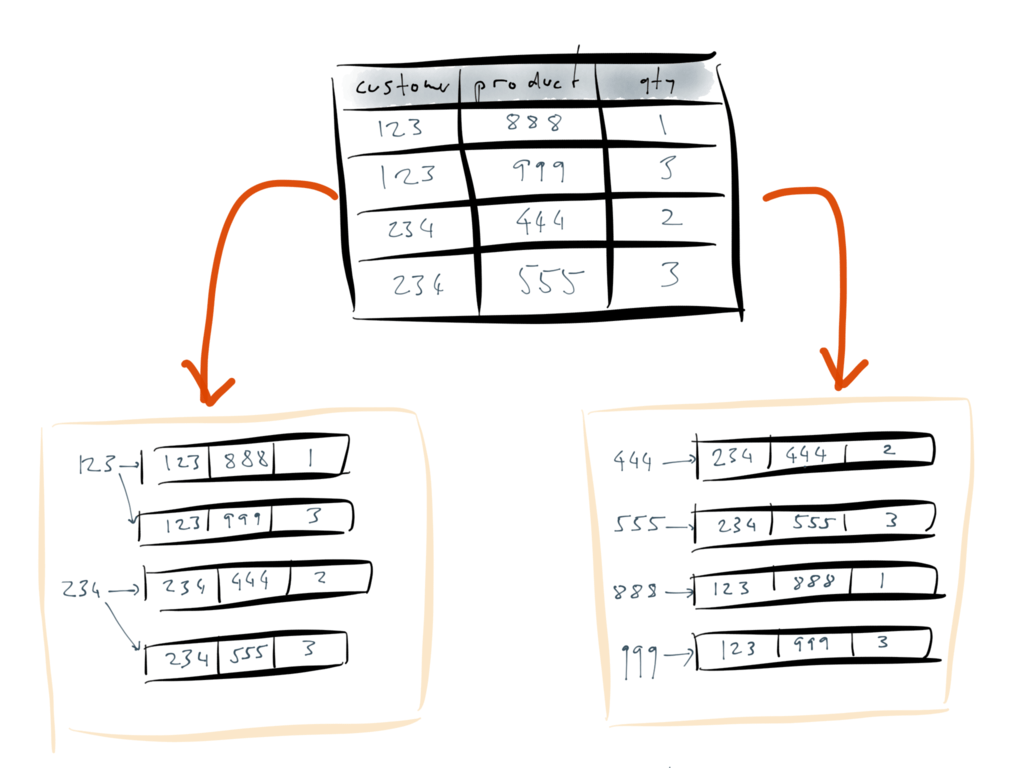
而事件溯源则记录用户的每一次添加商品、更新数量、提交订单操作,是有序的命令流:
实现Event Sourcing并不难,Event Store这款开源数据库就可以帮助我们存储事件以及进行复杂查询,还有很多新玩法等着我们去实践。
2. Stream processing(流处理)
Stream processing侧重于事件处理的过程,这里的事件的粒度偏向于实时的业务数据,Martin称之为Raw Event,如每秒的室内温度数据、用户当前发布的微博等,由于数据量大且实时要求高,流处理一般采用分布式架构。基于这些原始事件,可以构建上层的实时统计、聚合的逻辑,从而生成Aggregated Data,当然也可以构建离线分析的逻辑,所以原始事件是实现流处理的基础,聚合数据只是最终呈现的结果。
近年来随着Twitter、Facebook等互联网公司的发展,分布式流式计算逐渐成熟。这些互联网公司的业务数据有一个共同点,即有大量的并发的读写操作,在这种业务场景下传统的以关系型数据库为核心的系统架构已经不能胜任,只能将数据读写操作分离,构建新的解决方案,保证高可用性和高一致性。分布式流式计算是可以实现读写分离的一种架构,也正是读写分离让流处理和事件溯源的产生了逻辑上的内在一致性:在两种技术中事件在本质上讲都是数据的写操作,或者说是更新操作,流处理中的聚合数据和事件溯源里的状态及查询是数据读操作的结果: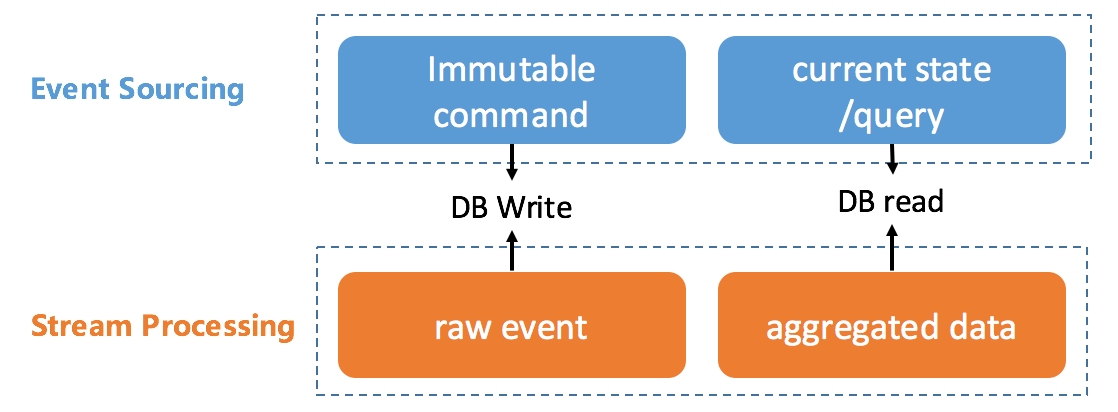
典型的分布式流式计算的架构是这样的: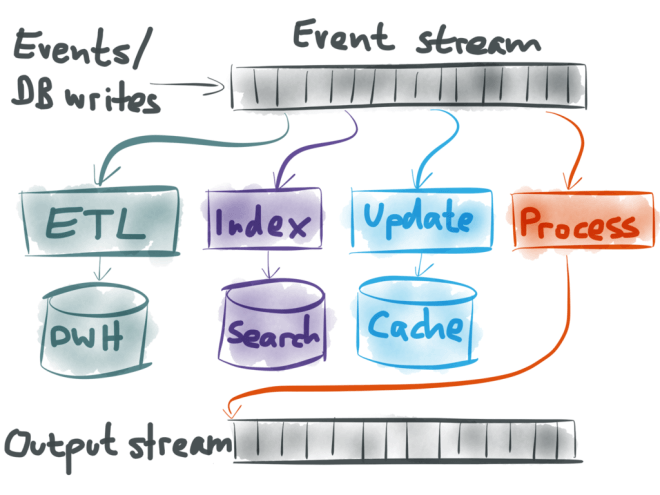
关于读写分离,Martin在文中还进行了一种有意思的抽象:应用程序里面产生后台交互的Button对应写操作,而Screen页面上展示的的结果对应读操作,虽然不够严谨但足以能够说明,事件的范畴在当前的Web端和Mobile端应用程序中已经不仅仅是传统的交易数据,用户的每一次点击动作和浏览记录都是能产生写操作事件,你打开淘宝的一瞬间,事件就会源源不断地产生,可谓“买卖未动,数据先行”。
3. Complex Event Processing(复杂事件处理)
CEP同样侧重于事件处理的过程,但是更强调事件之间存在复杂的关系,如时间顺序关系/聚合关系/层次关系/依赖关系。CEP需要构建规则引擎,对符合一定Pattern的事件进行查询和处理。这其中比较优秀的工具有Esper和Flink CEP。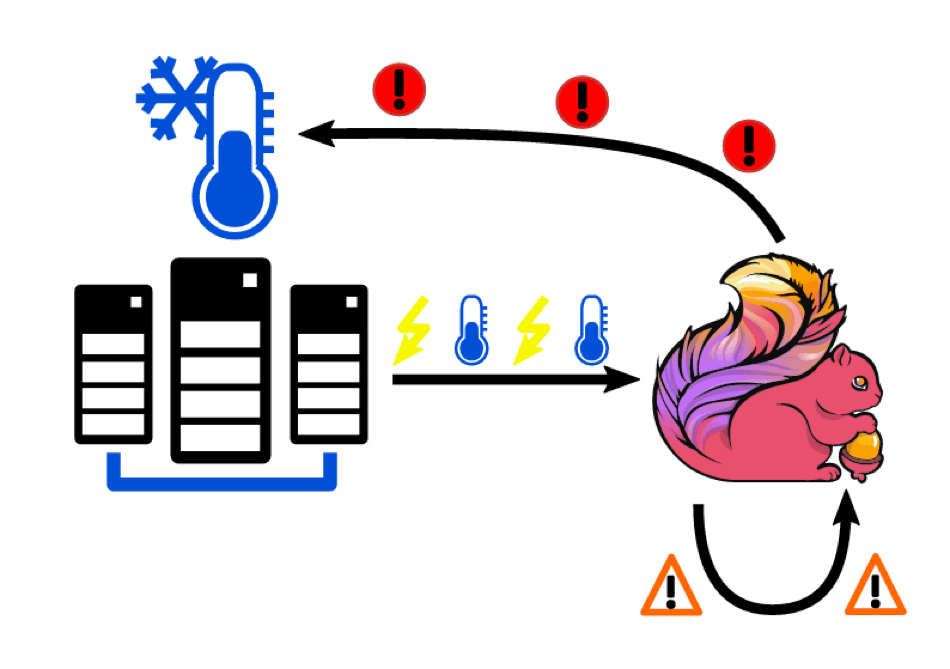
Flink官网的一个简单案例足以说明复杂事件处理和流处理结合后的威力:数据中心机架的温度被实时监控,温度超过阈值时会产生Warning事件,连续两个Warning事件会产生Alert事件,Alert事件则会触发降温的动作,在样的业务逻辑在Flink平台上用短短几行代码就可以实现,而用普通手段则要复杂得多。CEP可以提高系统的监控和分析能力。
4. CQRS (Command Query Responsibility Segregation,命令查询职责分离)
CQRS上升到了系统架构这个层次,事件的粒度是系统中的业务数据。在架构层面,将一个系统分为写入(命令)和查询两部分。一个命令表示一种意图,表示命令系统做什么修改,命令的执行结果通常不需要返回;一个查询表示向系统查询数据并返回。同样是读写分离,互联网场景下的流式计算中的读写分离是为了解决高并发读写操作,而CQRS中的读写分离则是为了解决复杂的数据模型,是Domain Driven Design(领域驱动设计)的实践。
5. Event-driven architecture(事件驱动架构)
在事件驱动架构中,事件的粒度为多进程、多服务、多系统之间的通信消息。不同于SOA架构,EDA架构是pub-sub模式:Process1处理完逻辑后产生消息,Process2订阅消息并进行处理, Process1不知道Process2的存在,Process间通过MQ最终数据的最终一致性。