Spark基本概念快速入门

Spark集群
一组计算机的集合,每个计算机节点作为独立的计算资源,又可以虚拟出多个具备计算能力的虚拟机,这些虚拟机是集群中的计算单元。Spark的核心模块专注于调度和管理虚拟机之上分布式计算任务的执行,集群中的计算资源则交给Cluster Manager这个角色来管理,Cluster Manager可以为自带的Standalone、或第三方的Yarn和Mesos。
Cluster Manager一般采用Master-Slave结构。以Yarn为例,部署ResourceManager服务的节点为Master,负责集群中所有计算资源的统一管理和分配;部署NodeManager服务的节点为Slave,负责在当前节点创建一个或多个具备独立计算能力的JVM实例,在Spark中,这些节点也叫做Worker。
另外还有一个Client节点的概念,是指用户提交Spark Application时所在的节点。
Application
用户自己写的Spark应用程序,批处理作业的集合。Application的main方法为应用程序的入口,用户通过Spark的API,定义了RDD和对RDD的操作。这里可以参考一段定义:
可以认为应用是多次批量计算组合起来的过程,在物理上可以表现为你写的程序包+部署配置。应用的概念类似于计算机中的程序,它只是一个蓝本,尚没有运行起来。——spark学习笔记三:spark原理介绍
SparkContext
Spark最重要的API,用户逻辑与Spark集群主要的交互接口,它会和Cluster Master交互,包括向它申请计算资源等。
Driver和Executor
Spark在执行每个Application的过程中会启动Driver和Executor两种JVM进程:
- Driver进程为主控进程,负责执行用户Application中的main方法,提交Job,并将Job转化为Task,在各个Executor进程间协调Task的调度。
- 运行在Worker上的Executor进程负责执行Task,并将结果返回给Driver,同时为需要缓存的RDD提供存储功能。

图片来源 - Spark Cluster Mode Overview
Spark有Client和Cluster两种部署Application的模式,Application以以Client模式部署时,Driver运行于Client节点,而以Cluster模式部署时,Driver运行于Worker节点,与Executor一样由Cluster Manager启动。
RDD
弹性分布式数据集,只读分区记录的集合,Spark对所处理数据的基本抽象。Spark中的计算可以简单抽象为对RDD的创建、转换和返回操作结果的过程:
- 创建
通过加载外部物理存储(如HDFS)中的数据集,或Application中定义的对象集合(如List)来创建。RDD在创建后不可被改变,只可以对其执行下面两种操作。 - 转换(Transformation)
对已有的RDD中的数据执行计算进行转换,而产生新的RDD,在这个过程中有时会产生中间RDD。Spark对于Transformation采用惰性计算机制,遇到Transformation时并不会立即计算结果,而是要等遇到Action时一起执行。 - 行动(Action)
对已有的RDD中的数据执行计算产生结果,将结果返回Driver程序或写入到外部物理存储。在Action过程中同样有可能生成中间RDD。
Partition(分区)
一个RDD在物理上被切分为多个Partition,即数据分区,这些Partition可以分布在不同的节点上。Partition是Spark计算任务的基本处理单位,决定了并行计算的粒度,而Partition中的每一条Record为基本处理对象。例如对某个RDD进行map操作,在具体执行时是由多个并行的Task对各自分区的每一条记录进行map映射。
Dependency(依赖)
对RDD的Transformation或Action操作,让RDD产生了父子依赖关系(事实上,Transformation或Action操作生成的中间RDD也存在依赖关系),这种依赖分为宽依赖和窄依赖两种:
- NarrowDependency (窄依赖)
parent RDD中的每个Partition最多被child RDD中的一个Partition使用。让RDD产生窄依赖的操作可以称为窄依赖操作,如map、union。 - WideDependency (或ShuffleDependency,宽依赖)
parent RDD中的每个Partition被child RDD中的多个Partition使用,这时会依据Record的key进行数据重组,这个过程即为Shuffle(洗牌)。让RDD产生kaun宽依赖的操作可以称为窄依赖操作,如reduceByKey, groupByKey。
Spark根据用户Application中的RDD的转换和行动,生成RDD之间的依赖关系,RDD之间的计算链构成了RDD的血统(Lineage),同时也生成了逻辑上的DAG(有向无环图)。每一个RDD都可以根据其依赖关系一级一级向前回溯重新计算,这便是Spark实现容错的一种手段:
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
——《Spark技术内幕》-第3章-RDD实现详解
Job
在一个Application中,以Action为划分边界的Spark批处理作业。前面提到,Spark采用惰性机制,对RDD的创建和转换并不会立即执行,只有在遇到第一个Action时才会生成一个Job,然后统一调度执行。一个Job包含N个Transformation和1个Action。
Shuffle
有一部分Transformation或Action会让RDD产生宽依赖,这样过程就像是将父RDD中所有分区的Record进行了“洗牌”(Shuffle),数据被打散重组,如属于Transformation操作的join,以及属于Action操作的reduce等,都会产生Shuffle。
Stage
一个Job中,以Shuffle为边界划分出的不同阶段。每个阶段包含一组可以被串行执行的窄依赖或宽依赖操作:
用户提交的计算任务是一个由RDD构成的DAG,如果RDD在转换的时候需要做Shuffle,那么这个Shuffle的过程就将这个DAG分为了不同的阶段(即Stage)。由于Shuffle的存在,不同的Stage是不能并行计算的,因为后面Stage的计算需要前面Stage的Shuffle的结果。
——《Spark技术内幕》-第4章-Scheduler模块详解
在对Job中的所有操作划分Stage时,一般会按照倒序进行,即从Action开始,遇到窄依赖操作,则划分到同一个执行阶段,遇到宽依赖操作,则划分一个新的执行阶段,且新的阶段为之前阶段的parent,然后依次类推递归执行。child Stage需要等待所有的parent Stage执行完之后才可以执行,这时Stage之间根据依赖关系构成了一个大粒度的DAG。
在一个Stage内,所有的操作以串行的Pipeline的方式,由一组Task完成计算。
Task
对一个Stage之内的RDD进行串行操作的计算任务。每个Stage由一组并发的Task组成(即TaskSet),这些Task的执行逻辑完全相同,只是作用于不同的Partition。一个Stage的总Task的个数由Stage中最后的一个RDD的Partition的个数决定。
Spark Driver会根据数据所在的位置分配计算任务,即把所有Task根据其Partition所在的位置分配给相应的Executor,以尽量减少数据的网络传输(这也就是所谓的移动数据不如移动计算)。一个Executor内同一时刻可以并行执行的Task数由总CPU数/每个Task占用的CPU数决定,即spark.executor.cores / spark.task.cpus。
Task分为ShuffleMapTask和ResultTask两种,位于最后一个Stage的Task为ResultTask,其他阶段的属于ShuffleMapTask。
Persist & Checkpoint
Persist
通过RDD的persist方法,可以将RDD的分区数据持久化在内存或硬盘中,通过cache方法则是缓存到内存。这里的persist和cache是一样的机制,只不过cache是使用默认的MEMORY_ONLY的存储级别对RDD进行persist,故“缓存”也就是一种“持久化”。
前面提到,只有触发了一个Action之后,Spark才会提交Job进行真正的计算。所以RDD只有经过一次Action之后,才能将RDD持久化,然后在Job间共享,即如果两个Job用到了相同的RDD,那么可以在第一个Job中对这个RDD进行缓存,在第二个Job中就避免了RDD的重新计算。持久化机制使需要访问重复数据的Application运行地更快,是能够提升Spark运算速度的一个重要功能。
Checkpoint
调用RDD的checkpoint方法,可以将RDD保存到外部存储中,如硬盘或HDFS。Spark引入checkpoint机制,是因为持久化的RDD的数据有可能丢失或被替换,checkpoint可以在这时候发挥作用,避免重新计算。
创建checkpoint是在当前Job完成后,由另外一个专门的Job完成:
也就是说需要checkpoint的RDD会被计算两次。因此,在使用rdd.checkpoint()的时候,建议加上rdd.cache(),这样第二次运行的Job久不用再去计算该rdd了。
——Apache Spark的设计与实现- Cache和Checkpoint功能
一个Job在开始处理RDD的Partition时,或者更准确点说,在Executor中运行的任务在获取Partition数据时,会先判断是否被持久化,在没有命中时再判断是否保存了checkpoint,如果没有读取到则会重新计算该Partition。
案例分析
这里借用@JerryLead的ComplexJob案例做一下分析:
1 | object complexJob { |
作者在这个例子中主要定义了一个对RDD的union和join操作,主要的RDD之间的关系如下图所示: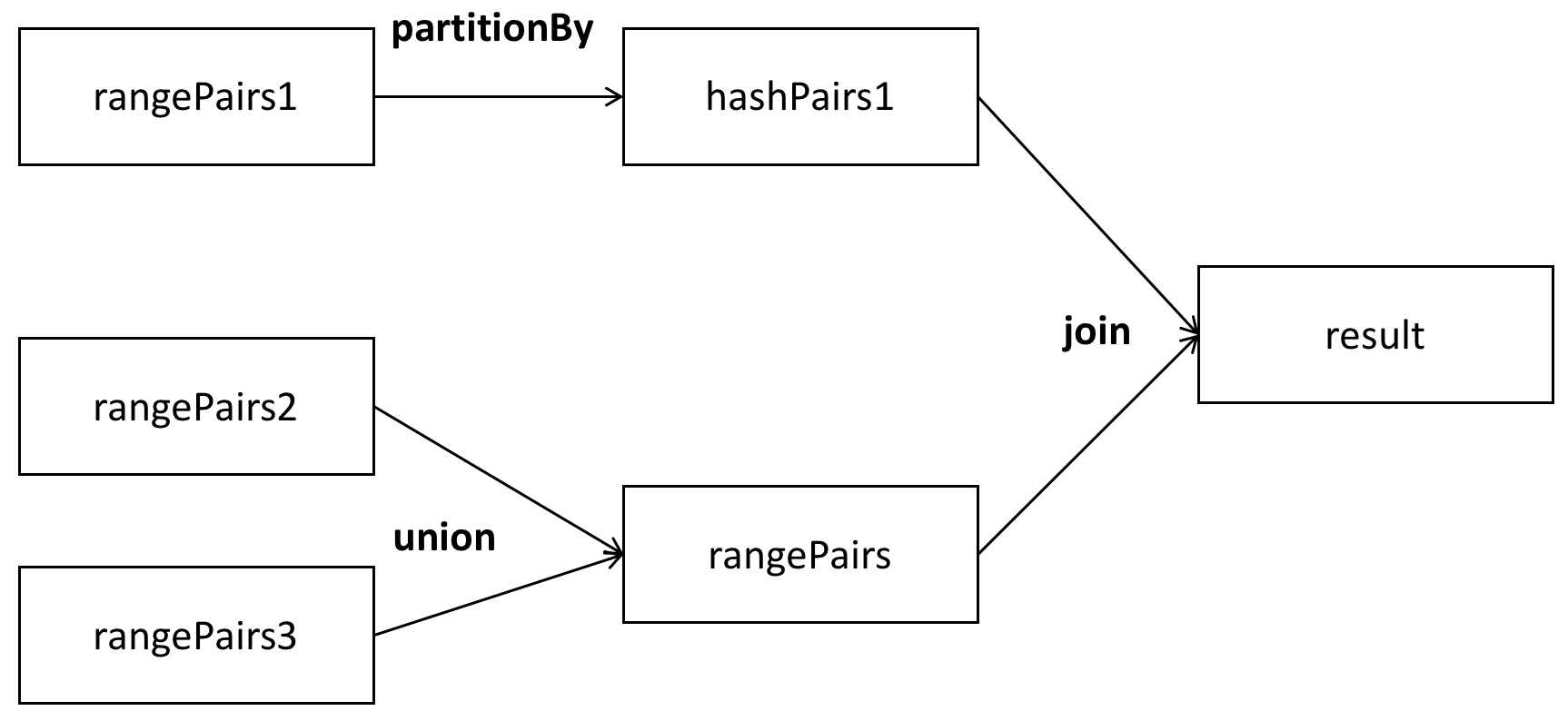
Job的物理执行图: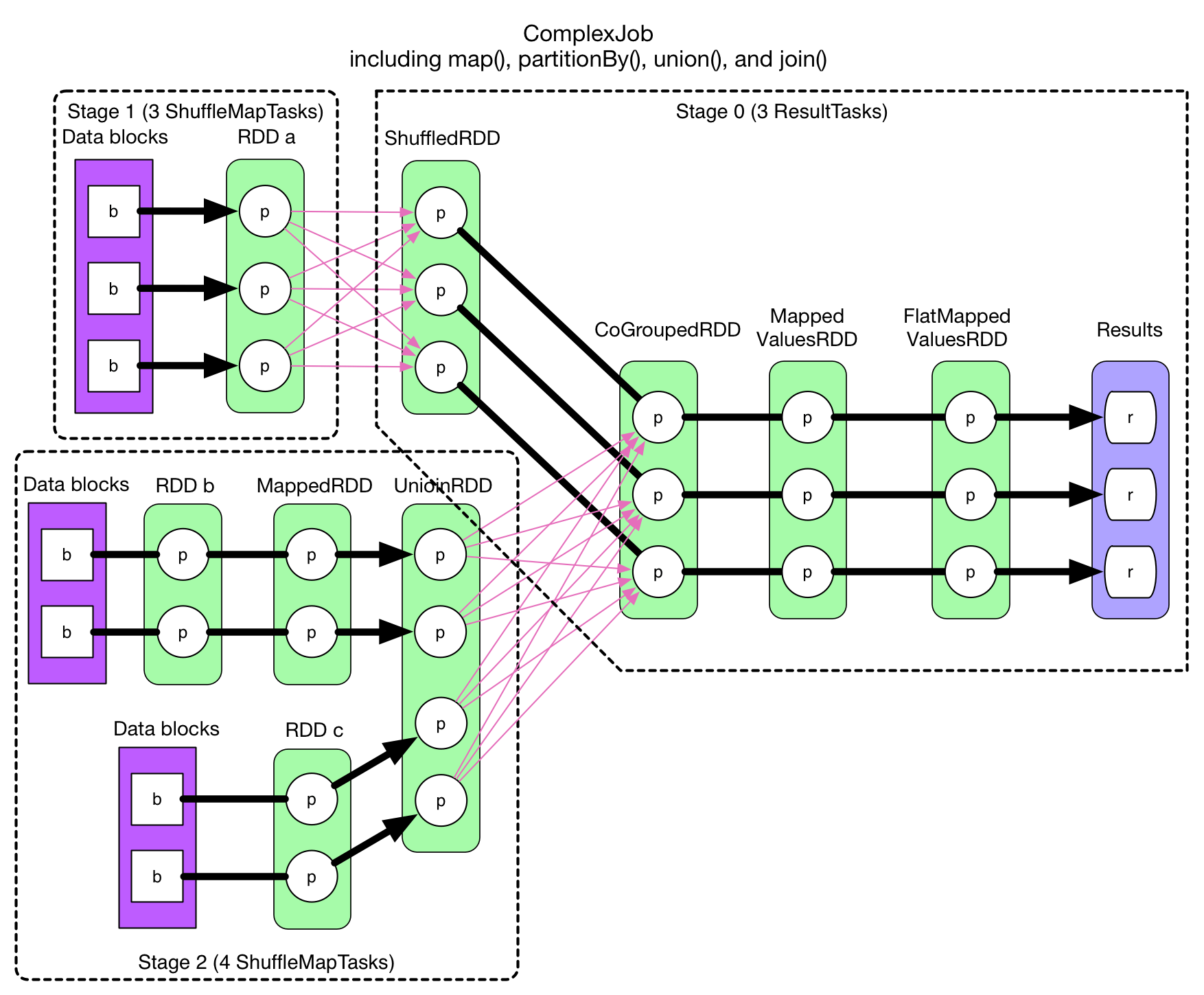
图片来源 - Job 物理执行图
参考作者画的物理执行图,我们可以观察到:
- 该Application仅有一个Job,由foreachWith这个Action触发。
- 这个Job中有三个Stage,partitionBy操作对RDD重新分区产生了Shuffle,是划分Stage0和Stage1的边界。join操作则是Stage2和Stage0的边界。
- 每个Stage的Task总数等于该阶段的最后一个RDD的Partition个数。
- 每个Task都是串行执行一个Stage内的所有操作。
- Transformation操作的过程中会产生中间RDD。